Birds of a Feather
Who Picks Your Team? Building a Fairer Way to Form Student Project Groups

Hampton Abbott & Carly Castillo — DTSC 2302, University of North Carolina at Charlotte Spring 2026
The moment everyone dreads
There is a small, predictable silence in every college classroom when an instructor says the words “For this next project, you’ll be in groups of four.” Some students immediately turn to the friends they came in with. Others freeze, hoping the instructor will assign teams so they don’t have to navigate the social cost of asking strangers. A few quietly recalculate the rest of their semester — who is going to do the work? who has my schedule? who’s going to ghost the group chat?
Group projects are everywhere in higher education, and yet the way teams get formed has barely changed in decades. Instructors typically choose between two options: let students pick (which reproduces existing social cliques and excludes newcomers), or assign randomly (which ignores the very things that determine whether a team functions — schedule, skill mix, work style). Neither option is satisfying, and neither scales well to a class of 30 students juggling jobs, commutes, and conflicting deadlines.
So we asked the obvious question: could a data-driven approach do better?
That question turned into the Teammate Matcher — a recommendation tool, not an autonomous decision-maker, that uses machine learning to surface team configurations an instructor can review and adjust. This post is the public-facing version of that work. The full mathematical write-up lives in the technical report on our project repository.
Why this matters beyond a class assignment
It is tempting to file “team formation” under minor logistical headache, but the choice of who works with whom is pedagogically consequential. Group composition shapes who learns from whom, who gets credit, who carries silent labor, and — at the limit — who passes a course (Kyprianidou et al., 2012). When those decisions are made by algorithm rather than by hand, the same set of questions that animates broader debates about AI in high-stakes domains shows up in miniature: Whose values are encoded in the model? Whose data does it use, and with what consent? Can the people affected by it understand what it’s doing? (O’Neil, 2016; Akgun & Greenhow, 2022)
Higher education has spent the last decade quietly importing data-driven decision systems — early-warning dashboards, automated tutoring placements, “engagement” analytics drawn from learning-management click streams. Most of these systems run without the consent of the students they classify and without the affected instructors fully understanding how they work. We wanted to take the opposite approach: build something narrow, transparent, opt-in, and explicitly designed to keep the instructor in charge.
Three questions, one project
Our work was guided by three research questions:
- How can we represent students’ skills, availability, and work styles using direct self-report — and is that data rich enough to drive useful matches?
- Which clustering or optimization algorithms produce the most balanced teams — and does the answer change when we optimize for similar teams versus complementary ones?
- Which student attributes actually drive cluster separation? In other words, what is the algorithm really listening to?
The third question is the most important one for understanding what the algorithm means. A model that produces good-looking teams but listens primarily to GPA, or to one cultural style of self-presentation, has different ethical implications than one that listens primarily to schedule overlap. Knowing which features dominate is not optional — it is the audit.
How we built it
The whole pipeline, end to end, looks like this:
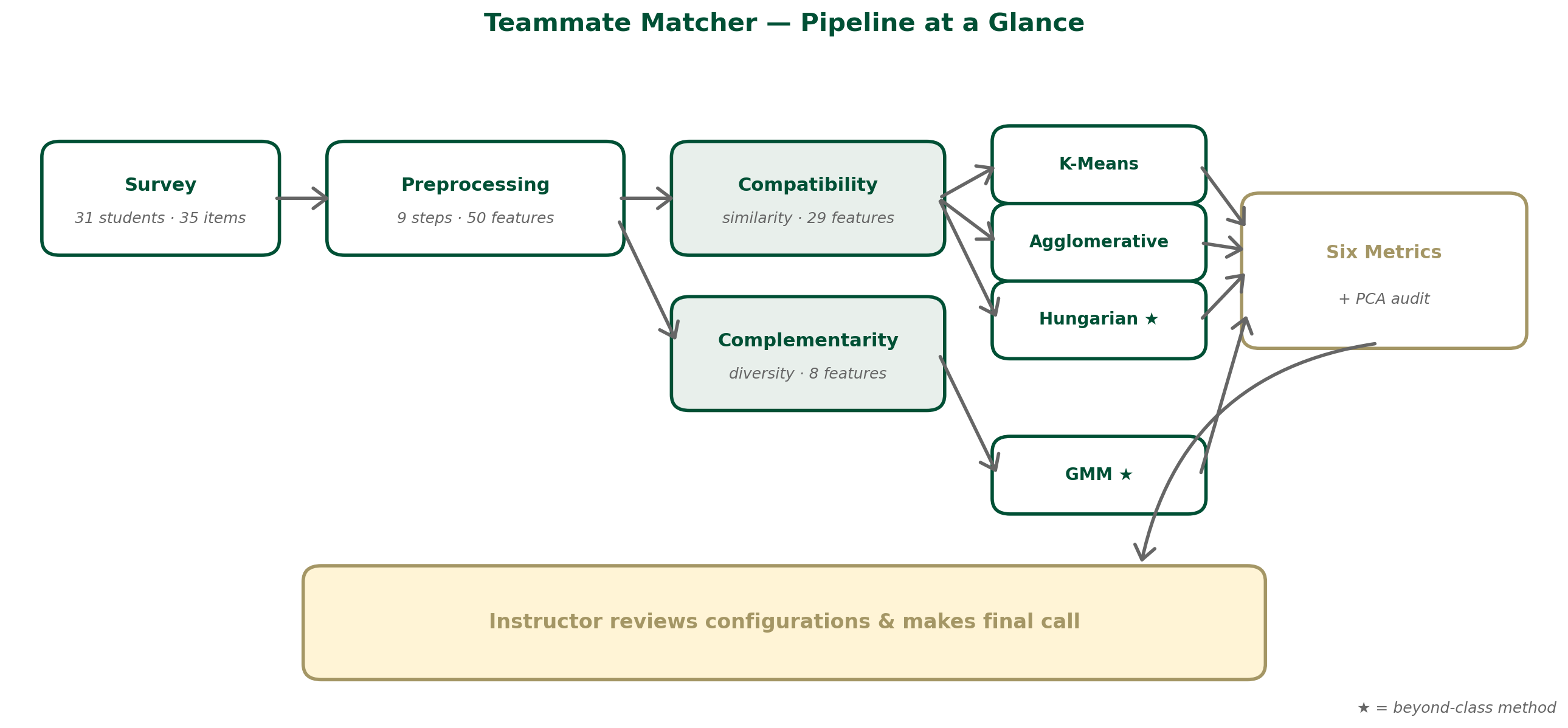
We deployed an anonymous Google Forms survey to 31 students in a single section of DTSC 2302. The survey collected 35 items across five domains: schedule and availability, technical skills (8 dimensions, self-rated 1–5), work style, communication preferences, and a small self-assessment block. After preprocessing — checkbox expansion, ordinal encoding, one-hot encoding, Min-Max normalization, and a privacy-preserving row shuffle — we ended up with 50 features per student and zero missing values.
We then ran four different models on the cleaned data, deliberately chosen to span the design space:
- K-Means clustering — the standard workhorse, fast and interpretable, but it cannot enforce balanced team sizes.
- Agglomerative (Ward) clustering — a hierarchical alternative that produces a dendrogram for instructor inspection and makes no spherical-cluster assumption.
- Hungarian Algorithm assignment — a combinatorial optimization technique from operations research (Kuhn, 1955). We used it to enforce that every team contains exactly 3–6 students, a property no standard clustering algorithm guarantees.
- Gaussian Mixture Model (GMM) — a probabilistic model that produces soft assignments instead of hard cluster labels (Bishop, 2006), which lets us flag ambiguous students for human review.
The first three models were applied to a similarity feature set (availability + work style) — the question they answer is “who has compatible schedules and styles?” GMM was applied to a complementarity feature set (skills only) — its question is “what are the latent skill archetypes in this cohort, and how can we mix them?”
We evaluated all four models on six metrics: three algorithmic (Silhouette Score, Davies–Bouldin, Calinski–Harabasz) that measure how cleanly clustered the partition is, and three domain-specific (intra-team skill variance, schedule overlap via Jaccard similarity, and skill coverage) that measure whether the resulting teams are actually deployable.
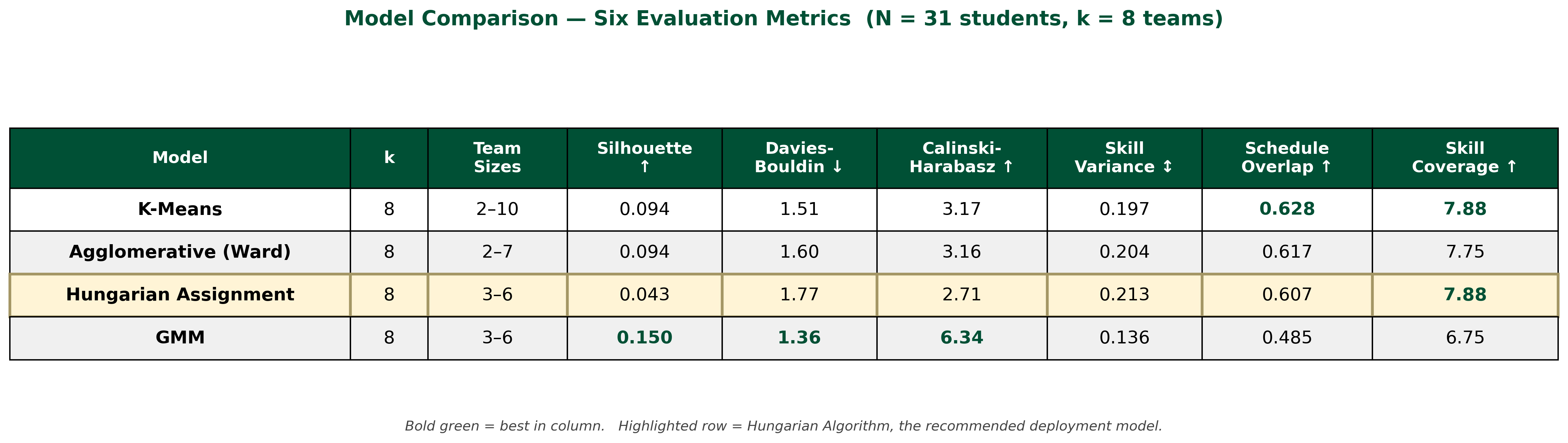
What we found
Three findings stood out, and not all of them were the ones we expected.
1. The Hungarian Algorithm is the model we’d actually deploy. It is the only one of the four that guaranteed every team contained between three and six students — the other models routinely produced oversized teams (one K-Means cluster contained 10 students) or two-person teams too small to cover the project’s required skills. It also tied for the highest skill coverage (7.875 out of 8 skill dimensions per team), meaning Hungarian-formed teams almost always had at least one member confident in each major skill area. Its silhouette score is the lowest of the four, which is the explicit cost of forcing balanced sizes — but for a deployment context, balanced and slightly-less-tight is far more useful than tight-but-unusable.
2. Schedule, not skill, is what separates students. Looking at the raw availability matrix gives the first hint:
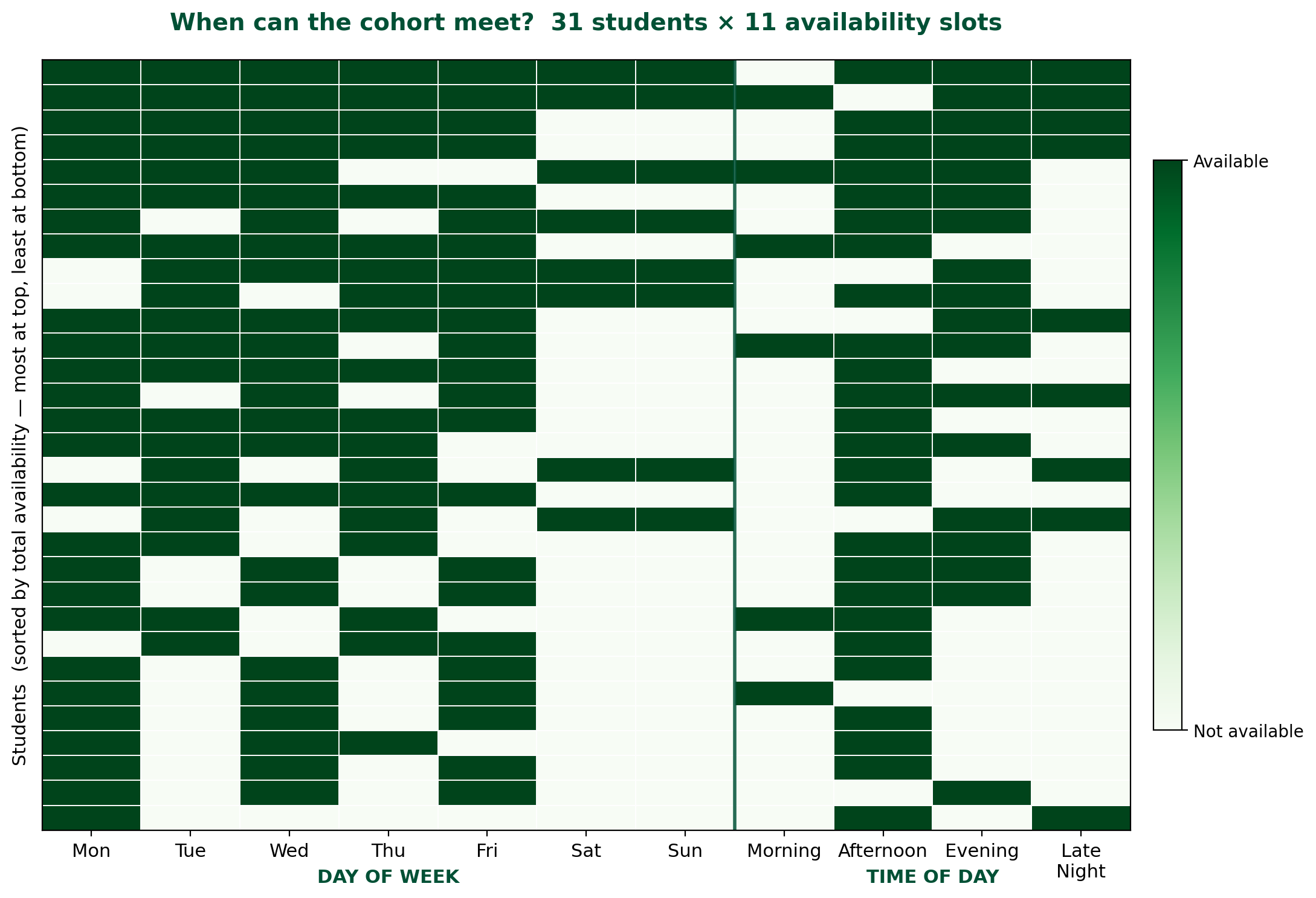
The heatmap shows uneven availability: weekday afternoons and evenings are dense, weekends and late-night slots are sparse, and individual students vary widely in how many slots they can offer. That heterogeneity is exactly the signal a clustering algorithm can latch onto.
When we ran Principal Component Analysis on the full feature set to formalize that intuition, the first principal component (15.8% of variance) was dominated by day-of-week availability — weekend, Tuesday, and Thursday loadings positive; Monday loading negative. The second component (13.5%) was conflict-handling and meeting-mode preferences. Self-rated skill features did not appear in the top loadings until the third principal component.
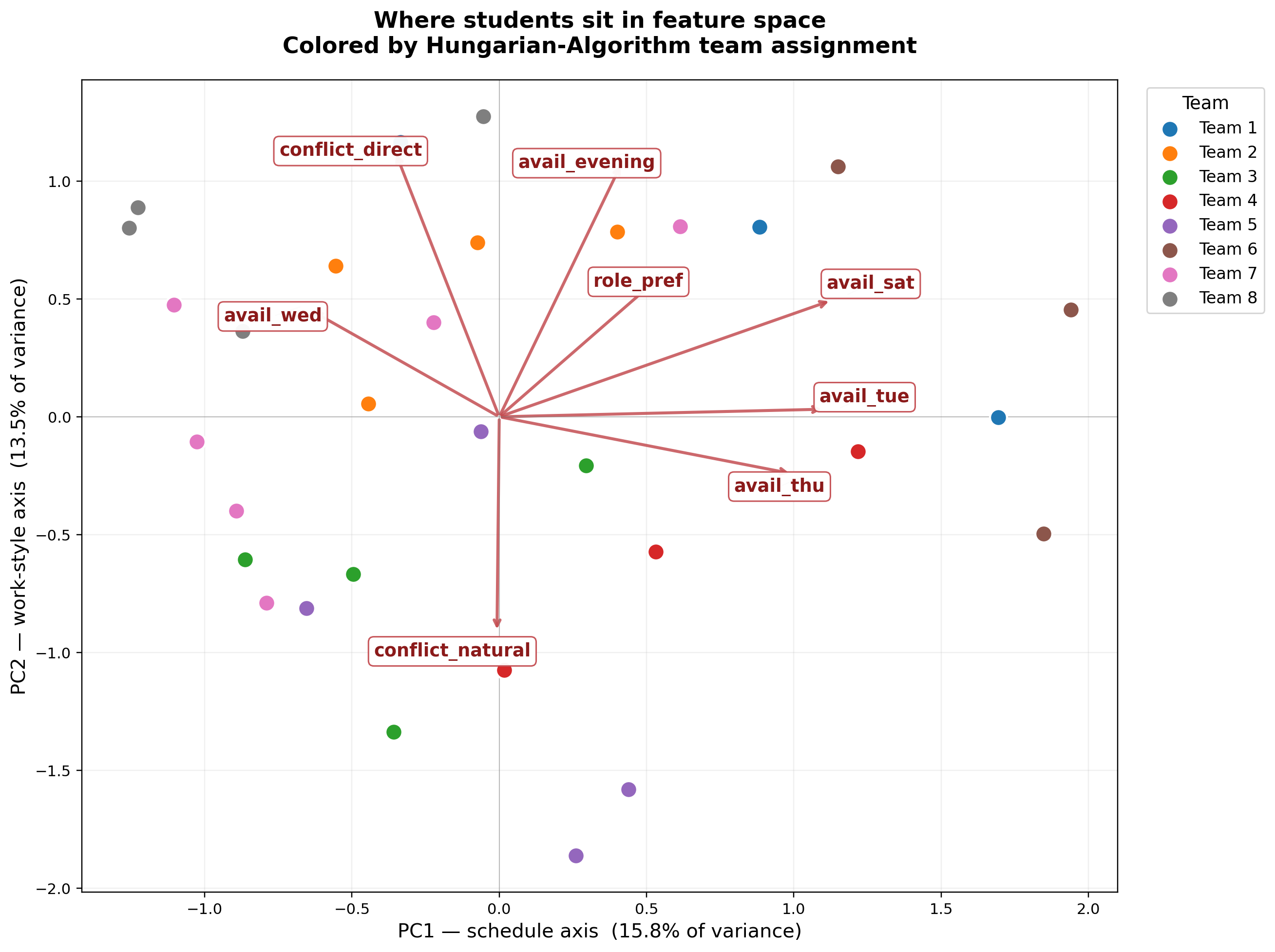
This is a pedagogically important finding. It means that within this cohort, students differentiate primarily on when they can meet and how they handle conflict — not on what they say they’re good at. Skills, in self-report at least, are surprisingly homogeneous. That has direct consequences for any future deployment: an algorithm that spends its energy matching on skills will have very little signal to work with.
3. GPA is not a neutral feature. We were curious whether including GPA in the feature set would meaningfully change team assignments. We ran K-Means with and without gpa_band and compared the resulting cluster labels using the Adjusted Rand Index — a standard measure of how similar two partitions are, where 1.0 is identical and 0.0 is random. The score was 0.34 — moderately low. Removing GPA actually improved the schedule-overlap metric slightly (0.628 versus 0.604). In other words, GPA was actively pulling the clustering away from its primary objective.
This was the most ethically significant finding in the project. GPA is a demographically loaded variable in the U.S. educational system (Eubanks, 2018; Selbst et al., 2019) — correlated with socioeconomic status, prior preparation, and access to academic support. A modeling decision as innocuous-sounding as “let’s include GPA as one of fifty features” turned out to reshape teams measurably, and not in a direction that helped. We had assumed GPA would be a passive ingredient. It wasn’t.
4. GMM produced sharp, not soft, archetypes. One of the design promises of GMM is that it returns probabilistic assignments — a vector of probabilities over latent components for each student — and we built an “ambiguity flag” intended to surface students whose maximum component probability fell below 0.60. In a larger or more diverse cohort, those flagged students would get instructor review.
In our cohort, zero students were flagged. Every single one of the 31 students locked tightly onto exactly one of the eight latent skill archetypes:
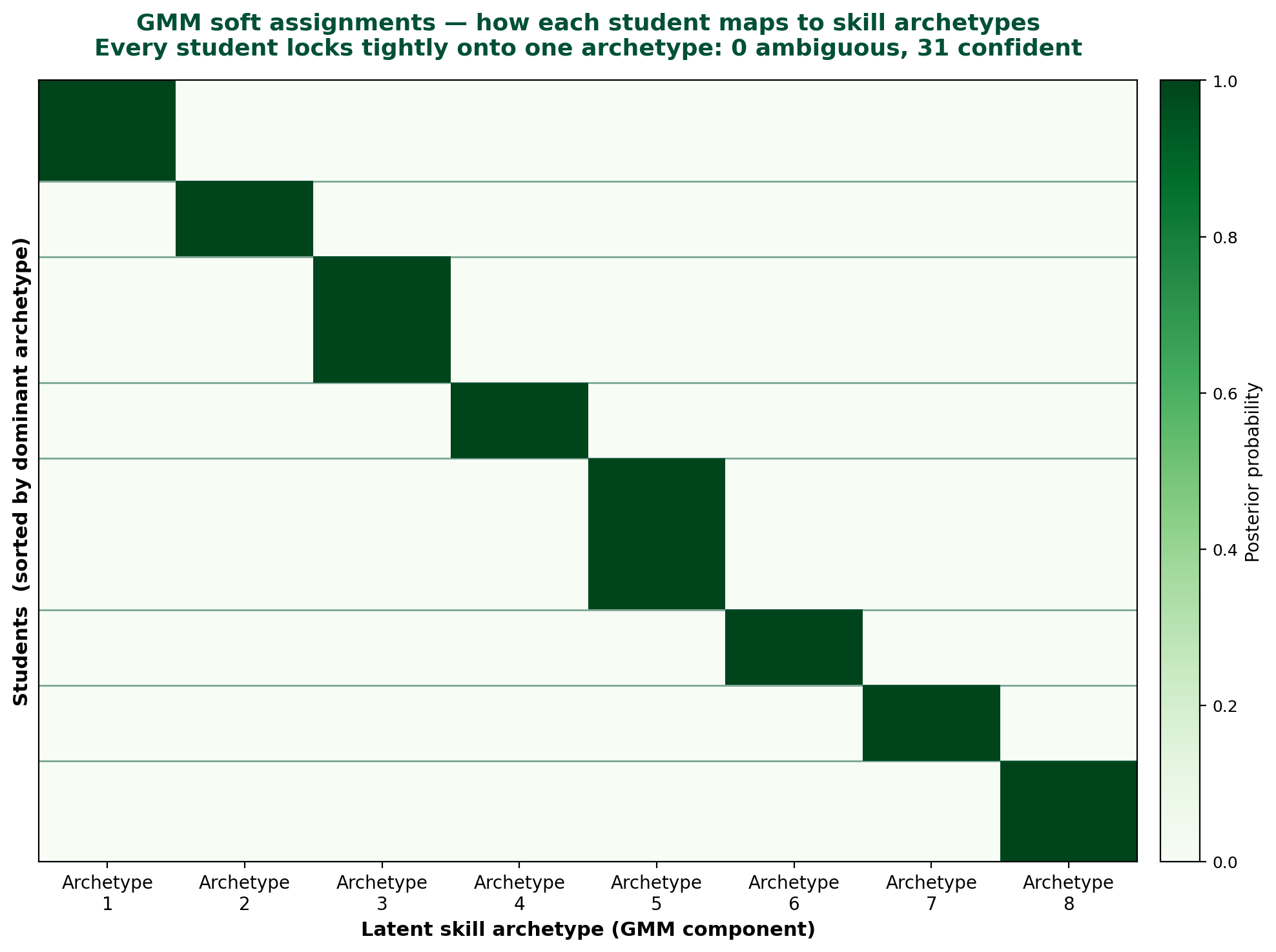
This is not a failure of the algorithm; it is a property of the data. With 31 students, 8 skill features, and 8 mixture components estimated with full covariance matrices, GMM has enough flexibility to fit each archetype tightly to its members. The ambiguity-flag mechanism still works as designed — it just had nothing to surface in this run. In a larger sample, or if we had restricted the covariance type to force softer assignments, we’d expect a meaningful number of borderline cases. The honest portfolio-post version of this finding is: the capability is real, the result on this cohort was clean, and a future run on richer data is the test that would actually exercise it.
The ethics, named explicitly
There are three ethical concerns worth surfacing — because the technical choices we made each have a social consequence, and because pretending otherwise would be dishonest about what we built.
Self-report bias is a fairness problem, not just a measurement problem. Students from cultures or backgrounds where confidence-expression is discouraged — or where humility is valued for its own sake — will systematically under-rate themselves on a 1-to-5 Likert scale (Akgun & Greenhow, 2022). An algorithm that takes those self-ratings at face value will route those students into “low-skill” team slots and route their more-confident peers into leadership-tagged ones. The Hungarian Algorithm’s size-balancing constraint mitigates this by forcing mixed teams, and our skill-coverage metric specifically asks whether anyone on the team meets each threshold, not whether everyone does. But the underlying bias remains in the data. We can’t fix it; we can only refuse to amplify it.
Algorithmic recommendations create anchoring pressure. Even with explicit human-in-the-loop framing, an instructor presented with a confident-looking algorithmic output is more likely to accept it than to override it (Akgun & Greenhow, 2022). To counter this, we deliberately produce multiple configurations rather than one, surface ambiguity flags from GMM (students with soft membership probability below 0.60), and present per-metric trade-offs rather than a single composite score. The point is to make scrutiny structurally easier than rubber-stamping.
Anonymous data isn’t always anonymous. Our raw survey data was collected anonymously — no names, no emails, no student IDs. But the Google Forms export included an exact-second timestamp for each submission, and in a class of 31 students who know each other, “who submitted at 11:30 AM on Wednesday” can identify someone. We treat the timestamp as a quasi-identifier: the raw file stays local and is never published, and the processed file is row-shuffled with a fixed random seed before being saved, breaking the correlation between row position and submission order. Reproducibility is preserved; re-identification is not.
Human in the loop, on purpose
The Teammate Matcher does not assign teams. It produces a set of candidate configurations with interpretable metrics — schedule overlap, skill coverage, ambiguity flags — and the instructor makes the final call. We made this choice deliberately, not as a hedge.
There are things the algorithm cannot see: known interpersonal conflicts, prior team history, accommodation needs, students currently navigating difficult life circumstances, the instructor’s pedagogical intent for that particular project. An autonomous system that overrides these is not a better system — it is a brittle one. The right place for an algorithm in this problem is upstream of the decision, surfacing options and quantifying trade-offs, not making the call.
What we’d do next
The most important piece of future work is validation: we need to know whether algorithmically formed teams actually report less friction and produce better outcomes than randomly assigned ones. That requires a post-project survey on team satisfaction, ideally run across multiple sections. Until that data exists, we have shown only that the algorithm produces plausibly good teams by our chosen metrics — not that it produces measurably better teams in lived experience.
We also plan to implement the equity constraint we currently document but don’t enforce: no team should be composed entirely of students who self-rate below threshold on any single skill dimension. And we want to compare Euclidean distance with Gower’s similarity, which handles mixed binary/continuous data more cleanly than either does individually.
A small claim
We started this project asking whether a data-driven tool could replace instructor judgment in team formation. We finished it convinced that the right framing is the inverse: a data-driven tool can protect instructor judgment by surfacing the trade-offs that hand-assignment makes implicit. The model is a magnifying glass, not a verdict. That distinction is small, but it is the entire ethical difference between a recommendation system and an automation system, and it is the difference we tried to design for.
References
Akgun, S., & Greenhow, C. (2022). Artificial intelligence in education: Addressing ethical challenges in K-12 settings. AI and Ethics, 2, 431–440. https://pmc.ncbi.nlm.nih.gov/articles/PMC8455229/
Bishop, C. M. (2006). Pattern recognition and machine learning. Springer.
Eubanks, V. (2018). Automating inequality: How high-tech tools profile, police, and punish the poor. St. Martin’s Press.
Kuhn, H. W. (1955). The Hungarian method for the assignment problem. Naval Research Logistics Quarterly, 2(1–2), 83–97. https://doi.org/10.1002/nav.3800020109
Kyprianidou, M., Demetriadis, S., Tsiatsos, T., & Pombortsis, A. (2012). Group formation based on learning styles: Can it improve students’ teamwork? Educational Technology Research and Development, 60(1), 83–110. https://doi.org/10.1007/s11423-011-9215-4
O’Neil, C. (2016). Weapons of math destruction: How big data increases inequality and threatens democracy. Crown.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., & Duchesnay, E. (2011). Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12, 2825–2830.
Selbst, A. D., Boyd, D., Friedler, S. A., Venkatasubramanian, S., & Vertesi, J. (2019). Fairness and abstraction in sociotechnical systems. In Proceedings of the Conference on Fairness, Accountability, and Transparency (pp. 59–68). https://doi.org/10.1145/3287560.3287598
Tools and Acknowledgments
Built in Python with scikit-learn (Pedregosa et al., 2011) for K-Means, Agglomerative, GMM, PCA, and evaluation metrics, and SciPy for the Hungarian Algorithm via linear_sum_assignment. Additional tools used: pandas, NumPy, matplotlib, and seaborn. Full source, preprocessing pipeline, model wrappers, evaluation code, and Jupyter notebooks are available at github.com/HPAuncc/teammate-matcher. Claude (Anthropic) was used as a coding assistant throughout development.
Special thanks to Aileen Benedict and Jordan Blekking (UNC Charlotte School of Data Science) for advising this project, and to the 31 anonymous DTSC 2302 students who took the survey.